Identity Hubs
Updated: June 2, 2020
This article introduces identity hubs and the technical concepts you need to understand when developing against them.
What is an identity hub?
In decentralized identity, public ledgers provide storage and distribution of identifiers and public keys. But you wouldn't want to store your sensitive personal data on these ledgers - considering they are immutable and sometimes, even public (such as, Bitcoin). We need a different solution for secure storage of personal data and information.
Identity hubs are decentralized off-chain personal data stores that give complete control and autonomy to their owner. They allow users to store their sensitive data - profile data, official documents, contact information, and more - in a way that prevents anyone from using their data without the user's explicit permission. Users can securely share their data with other people, apps, and businesses, giving access to the minimum data necessary and retaining a record of who has access to what. App developers can reduce the complexity of data management & compliance by storing sensitive data in the user's hub and reducing their own risk of data breach. Identity hubs enable a new wave of apps and services that respect a user's privacy and ownership of their personal information.
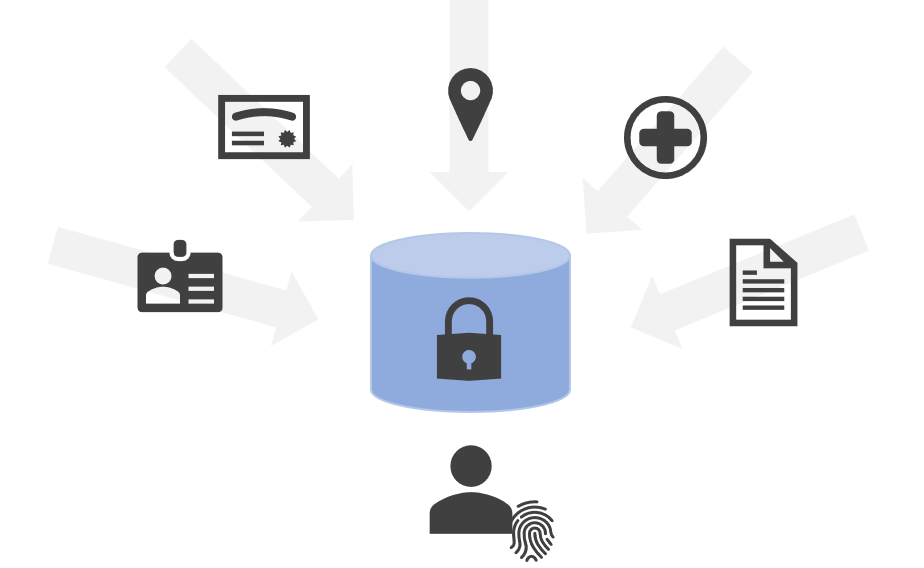
Identity hubs have several distinct characteristics that distinguish them from more traditional data storage solutions. The rest of this article describes each key feature of identity hubs and how they enable stronger user control over their data.
Standard APIs
So, what makes an identity hub decentralized?
The first aspect is that all identity hubs expose a standard interface for data storage and retrieval. This means that users can choose to run their identity hubs anywhere, with any identity hub provider they choose. Users can choose Microsoft as their hub provider or someone else entirely.
Each DID, when registered, can include a pointer to its identity hub in its DID document, in the service field as follows:
{
"document": {
"@context": "https://w3id.org/did/v1",
"publicKey": [
{
"id": "#key-1",
"type": "Secp256k1VerificationKey2018",
"publicKeyJwk": {
"kty": "EC",
"kid": "#key-1",
"crv": "P-256K",
"x": "Y4ezHen9MPuJcowKwhc9jT1owEzNb65BMUqtS7NH_C8",
"y": "wWDGd0PHYjIGRcP9owNvsSLYWzSbFLuCKE8KX75KFRY",
"use": "verify",
"defaultEncryptionAlgorithm": "none",
"defaultSignAlgorithm": "ES256K"
}
}
],
"service": [
{
"id": "IdentityHub",
"type": "IdentityHub",
"serviceEndpoint": {
"@context": "schema.identity.foundation/hub",
"@type": "UserServiceEndpoint",
"instance": [
"did:test:hub.id"
]
}
}
],
"id": "did:ion-test:EiDDNR0RyVI4rtKFeI8GpaSougQ36mr1ZJb8u6vTZOW6Vw"
},
"resolverMetadata": {
"driverId": "did:ion-test",
"driver": "HttpDriver",
"retrieved": "2019-05-10T20:07:17.489Z",
"duration": "152.6719ms"
}
}
Apps and services can use this pointer to locate and access data using the same APIs regardless of where the identity hub is running.
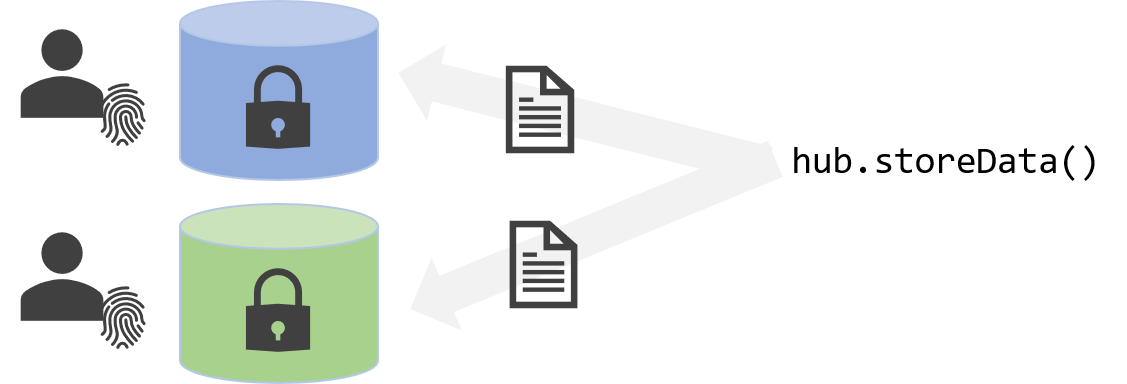
The identity hub standard interface is described in our Hub API reference document. It is currently being proposed to DIF and other standards bodies.
Furthermore, identity hubs are being developed as a suite of open-source packages. This helps new hub providers adhere to the standard APIs, and for advanced users to run their own identity hubs on their own infrastructure. The source code for identity hub packages can be found in DIF GitHub repositories.
The combination of standard APIs and open-source packages means that users can run their personal data store wherever they want, retaining full control over where their data is stored.
Interfaces
The identity hub standard API exposes a few "interfaces" that can be used for different purposes. The currently supported interfaces include:
| Interface | Description |
|---|---|
Collections |
The collections interface is the primary interface for storage of personal data. Any data that pertains to the user should be stored using this interface. |
Profile |
A special collection describing meta-data for a DID can be accessed using the profile interface. This might include the type of DID (user, business, or otherwise), names, and contact information, amongst other things. |
Permissions |
The permissions interface stores all access records to data. It is used to grant, review, and revoke access to data in the other interfaces. |
When programming against identity hubs, choose the interface that is most appropriate for your scenario. In most cases, this will be the Collections interface.
Semantic data model
As opposed to traditional data stores, an identity hub does not have a fixed schema or set of data it supports. Instead, hubs follow a semantic data model in which each piece of data self-contains all metadata necessary for interactions. As a simple example, a music playlist stored in a hub might be represented as:
{
"@context": "http://schema.org",
"@type": "MusicPlaylist",
"name": "Classic Rock Playlist",
"numTracks": "5",
"track": [
{
"byArtist": "Lynard Skynard",
"duration": "PT4M45S",
"inAlbum": "Second Helping",
"name": "Sweet Home Alabama",
}
]
}
In this example, the @context and @type metadata fields inform the hub that the object is a music playlist. The hub will then store the playlist alongside other music playlists of the same type within the Collections interface. Different applications can read and write music playlists in the user's hub, as long as they all agree on the same data structure for a music playlist. Globally standardized and industry-specific schemas, like schema.org, can help to ensure that applications all adhere to common data structures.
Using a standardized schema for data is not required, but recommended. And while the hub API design borrows from JSON-LD, identity hubs do not require the use of RDF, JSON-LD, Turtle, or any other linked data format. All that is required is that context and type metadata are used to describe any data stored in a hub.
At this time, identity hubs only support simple JSON data. Our hub service API tutorial describes how JSON data is sent to and from our cloud identity hub service. Images, videos, bytestreams, raw files, and other content types are not supported.
The semantic data model used by identity hubs ensures hubs serve as a generic personal data store that can handle a wide range of data - profile data, official documents, contact information, and much more.
Commits
Each individual piece of data in an identity hub is called an "object". And each object in an identity hub is comprised of a series of "commits".

A commit is similar to a git commit; it represents a change to an object. To write data to an identity hub, we need to construct and send a new commit to the hub. To read data from an identity hub, we need to fetch all commits from the hub. An object's current value can be constructed by applying all its commits in order.
The use of commits to represent data in identity hubs offers a few distinct advantages:
- it facilitates the hub's replication protocol, enabling multiple hub instances to sync data.
- it creates an auditable history of changes to an object, especially when each commit is signed by a DID.
- it eases implementation for use cases that need offline data modification and require conflict resolution.
The structure of a commit is determined by the commit "strategy" used for a particular piece of data. At this time, the identity hub only supports one commit strategy, known as the basic strategy. In the basic strategy, each commit contains the full data and metadata for the object. Using the music playlist example from above:
// Commit 1
{
"@context": "http://schema.org",
"@type": "MusicPlaylist",
"@committed_at": "2019-02-12T22:15:22Z",
"name": "Classic Rock Playlist",
"numTracks": "1",
"track": [
{
"byArtist": "Lynard Skynard",
"duration": "PT4M45S",
"inAlbum": "Second Helping",
"name": "Sweet Home Alabama",
}
]
}
// Commit 2
{
"@context": "http://schema.org",
"@type": "MusicPlaylist",
"@committed_at": "2019-02-12T22:16:47Z",
"name": "Classic Rock Playlist",
"numTracks": "0",
"track": []
}
// Commit 3
{
"@context": "http://schema.org",
"@type": "MusicPlaylist",
"@committed_at": "2019-02-13T22:16:47Z",
"name": "Classic Rock Playlist",
"numTracks": "1",
"track": [
{
"byArtist": "Jimi Hendrix",
"duration": "PT4M45S",
"inAlbum": "Axis: Bold As Love",
"name": "Castles Made of Sand",
}
]
}
In the basic strategy, the commit that was most recently written to the identity hub is the object's current value. So in the above example, Commit 3 would be the current value of the music playlist.
Alternative commit strategies may be introduced over time that employ more advanced commit structures and merge logic. But for now, only the basic strategy is supported.
The exact details of commits, including how to read and write them to identity hubs, are included in our hub service API reference and hub tutorials.
Permissions
Access to data in identity hubs is controlled through the Permissions interface using PermissionGrant objects. By rule, the DID that owns the identity hub always has full access to read, modify, write, and delete any and all data in an identity hub. The owner DID can create PermissionGrant objects in their hub that grant other DIDs the ability to access data. For instance:
{
"@context": "https://identity.foundation",
"@type": "PermissionGrant",
"owner": "did:example:abc123",
"grantee": "did:example:xyz456", // who is being granted access
"context": "https://schema.org",
"type": "MusicPlaylist", // what objects are being accessed
"allow": "-R--", // allows create, read, update, and delete
}
PermissionGrants are modeled just like any other object in the hub, and can be accessed through the Permissions interface. When this grant is created in an identity hub, it gives the DID did:example:xyz456 the permission to read all music playlists in the user's identity hub.
Permission grants have additional controls to restrict data access at a more granular level. For full details on the hub's permission system, refer to our hub service API reference.
The identity hub's permission system ensures that users retain full, fine-grained control over access to their data. As long as the user has sole access to their DID's private key(s), nobody else can give access to data. And because PermissionGrants are modified using commits, users retain an auditable log of who had access to what data at what times.
To learn more about the hub permissions system, please refer to DIF's hub documentation on GitHub.
Replication
Note
Identity hub replication is not yet available; it is still in development as of this writing.
Another aspect of identity hubs is that a single DID can have many hub instances. All hub instances replicate data to one another, so that the user's personal data store is distributed across several different physical data stores.
An identity hub can run in the cloud, on an edge device, or on any infrastructure that can implement the identity hub's replication protocol. This means that users do not have to rely on a single cloud provider, like Microsoft, to be the single source of truth for their personal information. Instead, users can keep a copy of their data on devices they physically own. They can also set up multiple cloud hub providers, to reduce risk that their data will become unavailable.
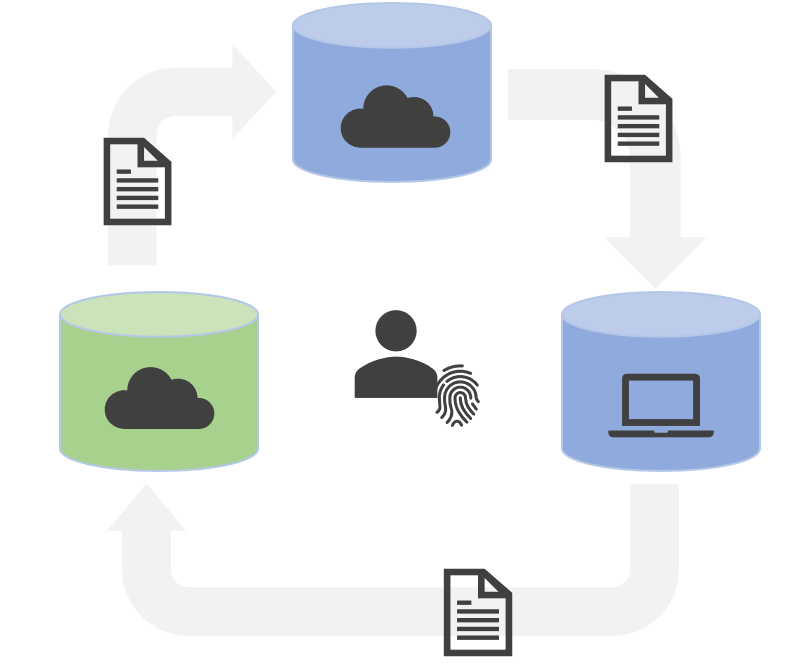
The hub replication protocol is still in development at this time. For our initial implementation, the underlying data store is Azure Cosmos DB. We're working on adding support for other database technologies before enabling replication between datastores.
Encryption
Note
Identity hub encryption is not yet available; it is still in development as of this writing.
The final aspect of identity hubs that ensures data protection is the hub's encryption subsystem. The goal of the hub's encryption system is to encrypt all data at the edge, before the data is ever passed to a hub instance. This way, the hub provider never sees an object's contents in clear text.
At this time, data encryption in the hub is still in development. In the meantime, our identity hub cloud service protects data in two other ways:
- Data sent on the wire to a hub is encrypted with the DID keys of the hub itself. This ensures data is confidential in transit.
- Data stored in our hub service is encrypted using traditional database encryption techniques. This helps ensure data is secure at rest.
These are the core concepts you may need to know when building apps against identity hubs. You're now ready to try hubs out! We recommend starting with the hub quick start tutorial here. If you have any questions or suggestions on how this document could be improved, please reach out to us.
See something missing? We'd love your feedback and input on the Verifiable Credentials preview. Please contact us. When you use Microsoft DID Services, you agree to the DID Preview Agreement and the Microsoft Privacy Statement.